Tool 1: sqoop-import:
Tool Syntax:
sqoop import (generic-args) (import tool-args)
or
sqoop-import (generic-args) (import tool-args)
Arguments are grouped into collections organized by function:
Following below:
We will cover each collection of arguments one by one,
1.Common arguments
Example 1: will cover the following arguments --connect, --connection-manager, --driver
hadoop@Mano:~$ sqoop import --connect jdbc:mysql://localhost/sqoop_test --connection-manager org.apache.sqoop.manager.GenericJdbcManager --driver com.mysql.jdbc.Driver --username root --password root --table student -m1;
Example 2: a file containing the authentication password using arugument --password-file
Steps to create password file:
Step 1:create a password file
hadoop@Mano:~$ echo -n "root">.password
Note:
-n - Do not output a trailing newline.
Step 2: move the password to HDFS location
hadoop@Mano:~$ hadoop fs -put .password /user/hadoop
Command:
hadoop@Mano:~$ sqoop import --connect jdbc:mysql://localhost/sqoop_test --username root
--password-file /user/hadoop/.password --table student -m 1;
Example 3:Read password from console
Command:
hadoop@Mano:~$ sqoop import --connect jdbc:mysql://localhost/sqoop_test --username root -P --table student -m 1;
Example 4: using argument --verbose, most prefer more debugging
Command:
hadoop@Mano:~$ sqoop import --connect jdbc:mysql://localhost/sqoop_test --username root -password root --table student -m 1 --verbose;
Example 5: using argument --connection-param-file , which hold the connection related key - value pairs
like this ==>sqoop.export.records.per.statement=1 save as separate .properties file and load using that argument
Status of Common arguments:
2.Validation arguments for More details:
Example 6: using argument --validate
Command:
mano@Mano:~$ sqoop import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees -m 1 --validate;
At the end of execute of tool, we can see the status of data validation
17/08/31 10:45:49 INFO mapreduce.JobBase: Validating the integrity of the import using the following configuration
Validator : org.apache.sqoop.validation.RowCountValidator
Threshold Specifier : org.apache.sqoop.validation.AbsoluteValidationThreshold
Failure Handler : org.apache.sqoop.validation.AbortOnFailureHandler
17/08/31 10:45:49 INFO validation.RowCountValidator: Data successfully validated
Example 7: using argument --validator <class>
Command:
mano@Mano:~$ sqoop import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees -m 1 --validator org.apache.sqoop.validation.RowCountValidator;
Example 8: using argument --validation-threshold <class>
Command:
mano@Mano:~$ sqoop import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees -m 1 --validation-threshold org.apache.sqoop.validation.AbsoluteValidationThreshold;
Example 9: using argument --validation-failurehandler <class>
Command:
mano@Mano:~$ sqoop import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees -m 1 --validation-failurehandler org.apache.sqoop.validation.AbortOnFailureHandler
Validation arguments status table:
3.Import control arguments:
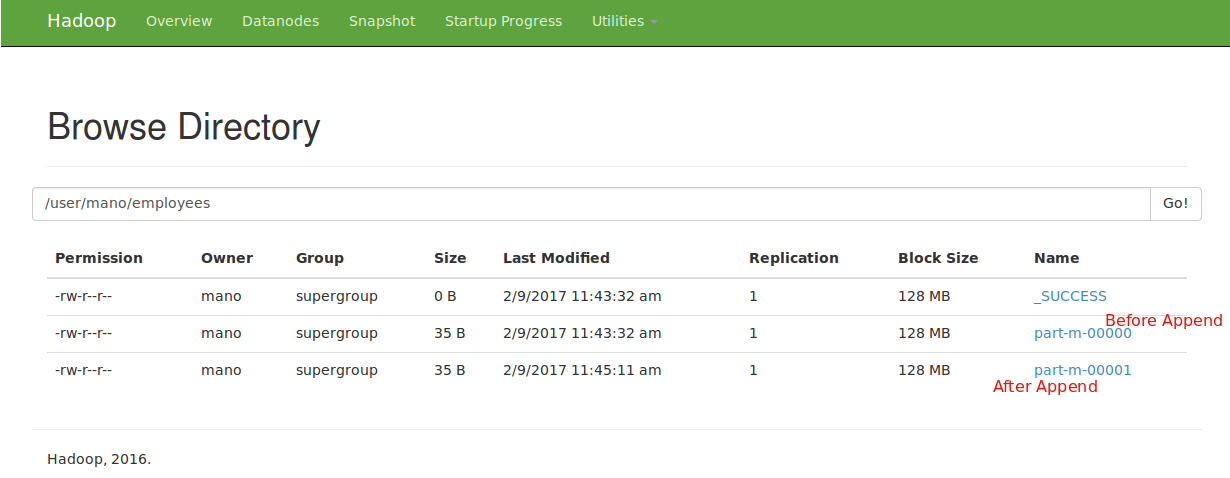
Example 10: using argument --append
it append's data to an existing dataset in HDFS(like new insertions on top of existing data)
mano@Mano:~$ sqoop import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees -m 1 --append
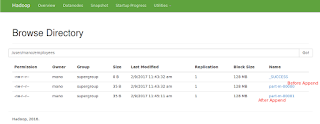 Note :So, it will create separate file for new data using append on existing import
Note :So, it will create separate file for new data using append on existing import
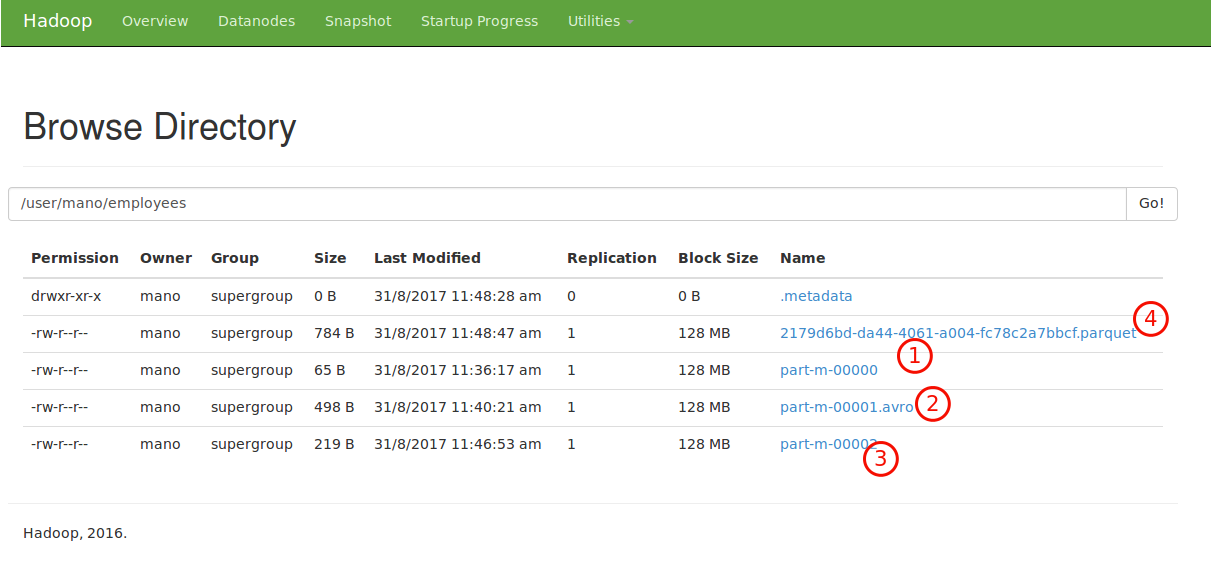
Example 11: using arguments for file formats by default --as-textfile, --as-avrodatafile, --as-sequencefile, --as-parquetfile
using default --as-textfile
mano@Mano:~$ sqoop-import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees --append -m 1;
using --as-avrodatafile
mano@Mano:~$ sqoop-import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees --append -m 1 --as-avrodatafile;
using --as-sequencefile
mano@Mano:~$ sqoop-import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees --append -m 1 --as-sequencefile;
using --as-parquetfile
mano@Mano:~$ hadosqoop-import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees --append -m 1 --as-parquetfile

Example 12: Using argument --boundary-query and --split-by to define the parallel import based on split column
Example:
BoundingValsQuery: SELECT MIN(`id`), MAX(`id`) FROM `employees`
Command:
mano@Mano:~$ sqoop-import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees --boundary-query 'select min(id),max(id) from employees' --split-by id --delete-target-dir
Example 13:Using argument --columns
Command:
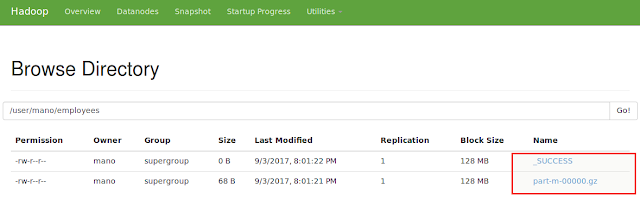
mano@Mano:~$ sqoop-import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees --columns id,name -m1 --delete-target-dir
Output: Data on HDFS after import from DB
mano@Mano:~$ hadoop fs -cat /user/mano/employees/par*
17/09/02 11:37:59 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
1,Mano
2,Prasath
3,Chella
4,Govind
Example 14: using arguments --autoreset-to-one-mapper, --delete-target-dir
Command:
mano@Mano:~$ sqoop-import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees --autoreset-to-one-mapper --delete-target-dir
Example 15: Using argument --query ,--target-dir, --where clause
Note:
While using --query argument must specify the target directory, else it fails
Command:
mano@Mano:~$ sqoop-import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --query 'select s.id,e.name from employees e join students s on e.id=s.id where $CONDITIONS' --target-dir '/MANO/Sqoop_import_tabl'e --split-by id --delete-target-dir
Example 16: Using argument --warehouse-dir , it will defines a parent directory for import but not the --target-dir
Command:
mano@Mano:~$ sqoop-import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees --warehouse-dir '/MANO/Sqoop_import_tabl'e --split-by id --delete-target-dir
Compressing Imported Data:
Before proceeding to read compression, make sure you have installed the codec on hadoop
If not please, use refer link ==> https://my-learnings-abouthadoop.blogspot.in/2017/09/snappy-installation-on-ubuntu.html
We need to use –compress option along with –compression-code with codec classname.
Below are the classname of compressions:
Classname:org.apache.hadoop.io.compress.GzipCodec
Command:
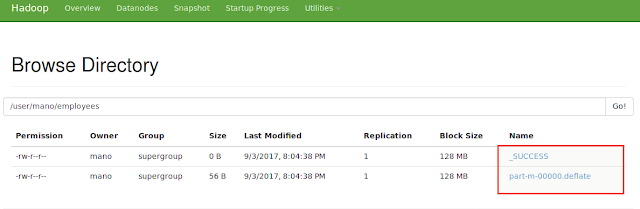
mano@Mano:~$ sqoop-import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees -m 1 --compress --compression-codec org.apache.hadoop.io.compress.GzipCodec --delete-target-dir
ii)DefaultCodec:
Classname:org.apache.hadoop.io.compress.DefaultCodec
Command:
mano@Mano:~$ sqoop-import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees -m 1 --compress --compression-codec org.apache.hadoop.io.compress.DefaultCodec --delete-target-dir
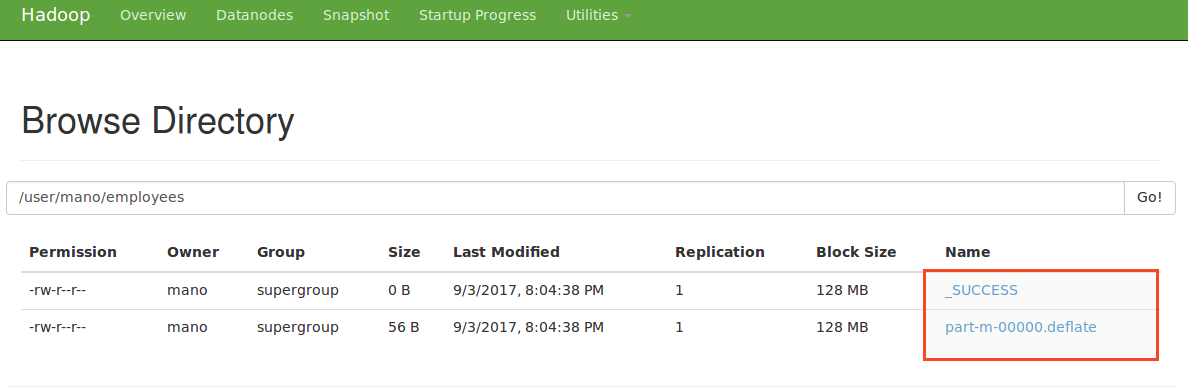
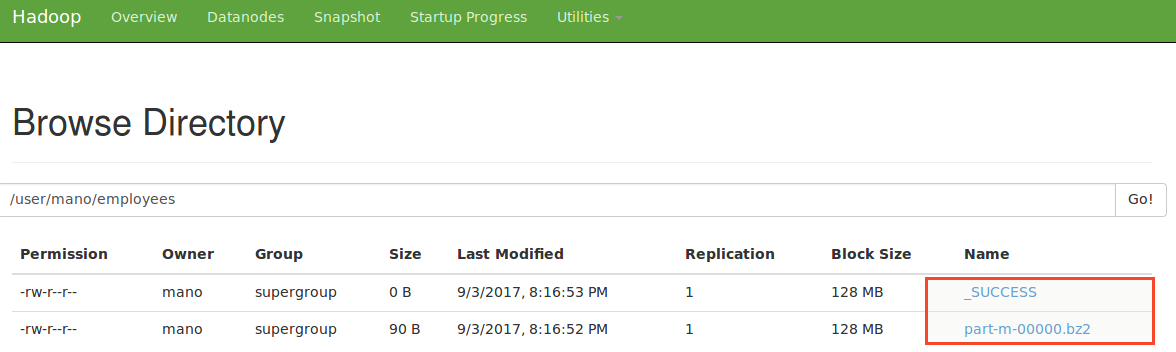
iii)BZip2 Compression:
Classname:org.apache.hadoop.io.compress.BZip2Codec
Command:
mano@Mano:~$ sqoop-import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees -m 1 --compress --compression-codec org.apache.hadoop.io.compress.BZip2Codec --delete-target-dir
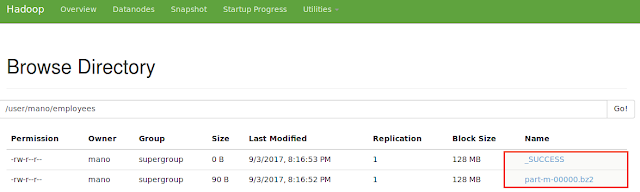
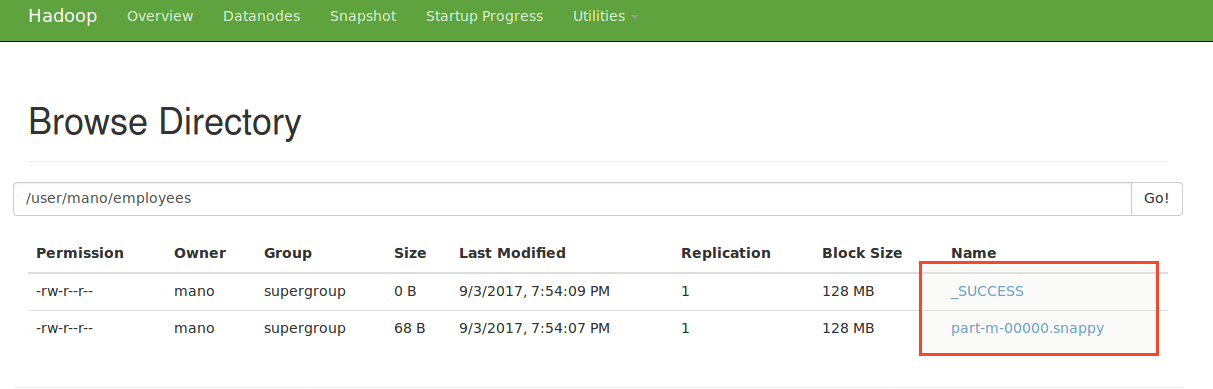
iv)Snappy Compression:
Classname: org.apache.hadoop.io.compress.SnappyCodec
Command:
mano@Mano:~$ sqoop-import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees -m 1 --compress --compression-codec org.apache.hadoop.io.compress.SnappyCodec --delete-target-dir

Import control arguments status table:
Note:
The --null-string and --null-non-string arguments are optional. If not specified, then the string "null" will be used.
4)Parameters for overriding mapping:
Sqoop is pre-configured to map most SQL types to appropriate Java or Hive representatives. However the default mapping might not be suitable in all the cases.
overridden by
--map-column-java = for changing mapping to Java
--map-column-hive = for changing Hive mapping
Syntax:
--map-column-java <name of column>=<new type>, <name of column>=<new type>..etc.,
i)--map-column-java argument
Command:
mano@Mano:~$ sqoop-import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table students --map-column-java id=Integer,name=String --autoreset-to-one-mapper
Parameters for overriding mapping status table:
Please follow the link for further ==>Sqoop_Page 4
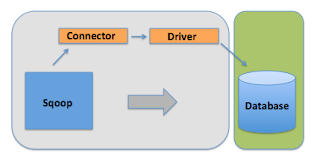
- Using the import tool imports an individual table from an RDBMS to HDFS.
- Each row from a table is represented as a separate record in HDFS.
- Records can be stored as text files (i.e,one record per line), or in binary representation as Avro or SequenceFiles.
Tool Syntax:
sqoop import (generic-args) (import tool-args)
or
sqoop-import (generic-args) (import tool-args)
Arguments are grouped into collections organized by function:
Following below:
- Common arguments
- Validation arguments More Details
- Import control arguments:
- Parameters for overriding mapping
- Incremental import arguments:
- Output line formatting arguments:
- Input parsing arguments:
- Hive arguments:
- HBase arguments:
- Accumulo arguments:
- Code generation arguments:
- Additional import configuration properties:
We will cover each collection of arguments one by one,
1.Common arguments
Argument
|
Description
|
--connect <jdbc-uri>
|
To Specify JDBC connect string containing hostname or
IP address (optionally port) followed by database name. It is mandatory
argument.
Example:–connect jdbc:mysql://localhost/sqoop_db |
--connection-manager <class-name>
|
Specify connection manager class name It is optional.
Example: –connection-manager org.apache.sqoop.manager.GenericJdbcManager |
--driver <class-name>
|
Manually specify JDBC driver class to use. Example:
com.mysql.jdbc.Driver
|
--hadoop-mapred-home <dir>
|
Override $HADOOP_MAPRED_HOME
|
--help
|
Print usage instructions
|
--password-file
|
Set path for a file containing the authentication
password
|
-P
|
Read password from console
|
--password <password>
|
Set authentication password
|
--username <username>
|
Set authentication username
|
--verbose
|
Print more information while working
|
--connection-param-file <filename>
|
Optional properties file that provides connection
parameters
|
--relaxed-isolation
|
Set connection transaction isolation to read
uncommitted for the mappers.
|
Example 1: will cover the following arguments --connect, --connection-manager, --driver
hadoop@Mano:~$ sqoop import --connect jdbc:mysql://localhost/sqoop_test --connection-manager org.apache.sqoop.manager.GenericJdbcManager --driver com.mysql.jdbc.Driver --username root --password root --table student -m1;
Example 2: a file containing the authentication password using arugument --password-file
Steps to create password file:
Step 1:create a password file
hadoop@Mano:~$ echo -n "root">.password
Note:
-n - Do not output a trailing newline.
Step 2: move the password to HDFS location
hadoop@Mano:~$ hadoop fs -put .password /user/hadoop
Command:
hadoop@Mano:~$ sqoop import --connect jdbc:mysql://localhost/sqoop_test --username root
--password-file /user/hadoop/.password --table student -m 1;
Example 3:Read password from console
Command:
hadoop@Mano:~$ sqoop import --connect jdbc:mysql://localhost/sqoop_test --username root -P --table student -m 1;
Example 4: using argument --verbose, most prefer more debugging
Command:
hadoop@Mano:~$ sqoop import --connect jdbc:mysql://localhost/sqoop_test --username root -password root --table student -m 1 --verbose;
Example 5: using argument --connection-param-file , which hold the connection related key - value pairs
like this ==>sqoop.export.records.per.statement=1 save as separate .properties file and load using that argument
Status of Common arguments:
Argument
|
Description
|
Example
|
--connect <jdbc-uri>
|
To Specify JDBC connect string containing hostname or
IP address (optionally port) followed by database name. It is mandatory
argument.
Example:–connect jdbc:mysql://localhost/sqoop_db |
Done
|
--connection-manager <class-name>
|
Specify connection manager class name It is optional.
Example: –connection-manager org.apache.sqoop.manager.GenericJdbcManager |
Done
|
--driver <class-name>
|
Manually specify JDBC driver class to use. Example:
com.mysql.jdbc.Driver
|
Done
|
--hadoop-mapred-home <dir>
|
Override $HADOOP_MAPRED_HOME
|
Need to try
|
--help
|
Print usage instructions
|
Done
|
--password-file
|
Set path for a file containing the authentication
password
|
Done
|
-P
|
Read password from console
|
Done
|
--password <password>
|
Set authentication password
|
Done
|
--username <username>
|
Set authentication username
|
Done
|
--verbose
|
Print more information while working
|
Done
|
--connection-param-file <filename>
|
Optional properties file that provides connection
parameters
|
Need to try
|
--relaxed-isolation
|
Set connection transaction isolation to read
uncommitted for the mappers.
|
Need to try
|
2.Validation arguments for More details:
| Argument | Description |
| --validate | Enable validation of data copied, supports single table copy only. |
| --validator <class-name> | Specify validator class to use. |
| --validation-threshold <class-name> | Specify validation threshold class to use. |
| --validation-failurehandler <class-name> | Specify validation failure handler class to use. |
Example 6: using argument --validate
Command:
mano@Mano:~$ sqoop import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees -m 1 --validate;
At the end of execute of tool, we can see the status of data validation
17/08/31 10:45:49 INFO mapreduce.JobBase: Validating the integrity of the import using the following configuration
Validator : org.apache.sqoop.validation.RowCountValidator
Threshold Specifier : org.apache.sqoop.validation.AbsoluteValidationThreshold
Failure Handler : org.apache.sqoop.validation.AbortOnFailureHandler
17/08/31 10:45:49 INFO validation.RowCountValidator: Data successfully validated
Example 7: using argument --validator <class>
Command:
mano@Mano:~$ sqoop import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees -m 1 --validator org.apache.sqoop.validation.RowCountValidator;
Example 8: using argument --validation-threshold <class>
Command:
mano@Mano:~$ sqoop import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees -m 1 --validation-threshold org.apache.sqoop.validation.AbsoluteValidationThreshold;
Example 9: using argument --validation-failurehandler <class>
Command:
mano@Mano:~$ sqoop import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees -m 1 --validation-failurehandler org.apache.sqoop.validation.AbortOnFailureHandler
Validation arguments status table:
| Argument | Description | Example |
| --validate | Enable validation of data copied, supports single table copy only. | Done |
| --validator <class-name> | Specify validator class to use. | Done |
| --validation-threshold <class-name> | Specify validation threshold class to use. | Done |
| --validation-failurehandler <class-name> | Specify validation failure handler class to use. | Done |
3.Import control arguments:
| Argument | Description |
| --append | Append data to an existing dataset in HDFS |
| --as-avrodatafile | Imports data to Avro Data Files |
| --as-sequencefile | Imports data to SequenceFiles |
| --as-textfile | Imports data as plain text (default) |
| --as-parquetfile | Imports data to Parquet Files |
| --boundary-query <statement> | Boundary query to use for creating splits |
| --columns <col,col,col…> | Columns to import from table |
| --delete-target-dir | Delete the import target directory if it exists |
| --direct | Use direct connector if exists for the database |
| --fetch-size <n> | Number of entries to read from database at once. |
| --inline-lob-limit <n> | Set the maximum size for an inline LOB |
| -m,--num-mappers <n> | Use n map tasks to import in parallel |
| -e,--query <statement> | Import the results of statement. |
| --split-by <column-name> | Column of the table used to split work units. Cannot be used with --autoreset-to-one-mapper option. |
| --autoreset-to-one-mapper | Import should use one mapper if a table has no primary key and no split-by column is provided. Cannot be used with --split-by <col> option. |
| --table <table-name> | Table to read |
| --target-dir <dir> | HDFS destination dir |
| --warehouse-dir <dir> | HDFS parent for table destination |
| --where <where clause> | WHERE clause to use during import |
| -z,--compress | Enable compression |
| --compression-codec <c> | Use Hadoop codec (default gzip) |
| --null-string <null-string> | The string to be written for a null value for string columns |
| --null-non-string <null-string> | The string to be written for a null value for non-string columns |
Example 10: using argument --append
it append's data to an existing dataset in HDFS(like new insertions on top of existing data)
mano@Mano:~$ sqoop import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees -m 1 --append
Example 11: using arguments for file formats by default --as-textfile, --as-avrodatafile, --as-sequencefile, --as-parquetfile
using default --as-textfile
mano@Mano:~$ sqoop-import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees --append -m 1;
using --as-avrodatafile
mano@Mano:~$ sqoop-import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees --append -m 1 --as-avrodatafile;
using --as-sequencefile
mano@Mano:~$ sqoop-import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees --append -m 1 --as-sequencefile;
using --as-parquetfile
mano@Mano:~$ hadosqoop-import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees --append -m 1 --as-parquetfile
Example 12: Using argument --boundary-query and --split-by to define the parallel import based on split column
Example:
BoundingValsQuery: SELECT MIN(`id`), MAX(`id`) FROM `employees`
Command:
mano@Mano:~$ sqoop-import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees --boundary-query 'select min(id),max(id) from employees' --split-by id --delete-target-dir
Example 13:Using argument --columns
Command:
mano@Mano:~$ sqoop-import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees --columns id,name -m1 --delete-target-dir
Output: Data on HDFS after import from DB
mano@Mano:~$ hadoop fs -cat /user/mano/employees/par*
17/09/02 11:37:59 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
1,Mano
2,Prasath
3,Chella
4,Govind
Example 14: using arguments --autoreset-to-one-mapper, --delete-target-dir
Command:
mano@Mano:~$ sqoop-import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees --autoreset-to-one-mapper --delete-target-dir
Example 15: Using argument --query ,--target-dir, --where clause
Note:
While using --query argument must specify the target directory, else it fails
Command:
mano@Mano:~$ sqoop-import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --query 'select s.id,e.name from employees e join students s on e.id=s.id where $CONDITIONS' --target-dir '/MANO/Sqoop_import_tabl'e --split-by id --delete-target-dir
Example 16: Using argument --warehouse-dir , it will defines a parent directory for import but not the --target-dir
Command:
mano@Mano:~$ sqoop-import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees --warehouse-dir '/MANO/Sqoop_import_tabl'e --split-by id --delete-target-dir
Compressing Imported Data:
Before proceeding to read compression, make sure you have installed the codec on hadoop
If not please, use refer link ==> https://my-learnings-abouthadoop.blogspot.in/2017/09/snappy-installation-on-ubuntu.html
We need to use –compress option along with –compression-code with codec classname.
Below are the classname of compressions:
- org.apache.hadoop.io.compress.GzipCodec
- org.apache.hadoop.io.compress.DefaultCodec
- org.apache.hadoop.io.compress.BZip2Codec
- org.apache.hadoop.io.compress.SnappyCodec
Classname:org.apache.hadoop.io.compress.GzipCodec
Command:
mano@Mano:~$ sqoop-import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees -m 1 --compress --compression-codec org.apache.hadoop.io.compress.GzipCodec --delete-target-dir

ii)DefaultCodec:
Classname:org.apache.hadoop.io.compress.DefaultCodec
Command:
mano@Mano:~$ sqoop-import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees -m 1 --compress --compression-codec org.apache.hadoop.io.compress.DefaultCodec --delete-target-dir
iii)BZip2 Compression:
Classname:org.apache.hadoop.io.compress.BZip2Codec
Command:
mano@Mano:~$ sqoop-import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees -m 1 --compress --compression-codec org.apache.hadoop.io.compress.BZip2Codec --delete-target-dir
iv)Snappy Compression:
Classname: org.apache.hadoop.io.compress.SnappyCodec
Command:
mano@Mano:~$ sqoop-import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table employees -m 1 --compress --compression-codec org.apache.hadoop.io.compress.SnappyCodec --delete-target-dir
Import control arguments status table:
| Argument | Description | Example |
| --append | Append data to an existing dataset in HDFS | Done |
| --as-avrodatafile | Imports data to Avro Data Files | Done |
| --as-sequencefile | Imports data to SequenceFiles | Done |
| --as-textfile | Imports data as plain text (default) | Done |
| --as-parquetfile | Imports data to Parquet Files | Done |
| --boundary-query <statement> | Boundary query to use for creating splits | Done |
| --columns <col,col,col…> | Columns to import from table | Done |
| --delete-target-dir | Delete the import target directory if it exists | Done |
| --direct | Use direct connector if exists for the database | Need to check |
| --fetch-size <n> | Number of entries to read from database at once. | Need to check |
| --inline-lob-limit <n> | Set the maximum size for an inline LOB | Need to check |
| -m,--num-mappers <n> | Use n map tasks to import in parallel | Done |
| -e,--query <statement> | Import the results of statement. | Done |
| --split-by <column-name> | Column of the table used to split work units. Cannot be used with --autoreset-to-one-mapper option. | Done |
| --autoreset-to-one-mapper | Import should use one mapper if a table has no primary key and no split-by column is provided. Cannot be used with --split-by <col> option. | Done |
| --table <table-name> | Table to read | Done |
| --target-dir <dir> | HDFS destination dir | Done |
| --warehouse-dir <dir> | HDFS parent for table destination | Done |
| --where <where clause> | WHERE clause to use during import | Done |
| -z,--compress | Enable compression | Done |
| --compression-codec <c> | Use Hadoop codec (default gzip) | Done |
| --null-string <null-string> | The string to be written for a null value for string columns | Need to check |
| --null-non-string <null-string> | The string to be written for a null value for non-string columns | Need to check |
Note:
The --null-string and --null-non-string arguments are optional. If not specified, then the string "null" will be used.
4)Parameters for overriding mapping:
Sqoop is pre-configured to map most SQL types to appropriate Java or Hive representatives. However the default mapping might not be suitable in all the cases.
overridden by
--map-column-java = for changing mapping to Java
--map-column-hive = for changing Hive mapping
| Argument | Description |
| --map-column-java <mapping> | Override mapping from SQL to Java type for configured columns. |
| --map-column-hive <mapping> | Override mapping from SQL to Hive type for configured columns. |
Syntax:
--map-column-java <name of column>=<new type>, <name of column>=<new type>..etc.,
i)--map-column-java argument
Command:
mano@Mano:~$ sqoop-import --connect jdbc:mysql://localhost/sqoop_test --username root --password root --table students --map-column-java id=Integer,name=String --autoreset-to-one-mapper
Parameters for overriding mapping status table:
| Argument | Description | Example |
| --map-column-java <mapping> | Override mapping from SQL to Java type for configured columns. | Done |
| --map-column-hive <mapping> | Override mapping from SQL to Hive type for configured columns. | Need to check |
Please follow the link for further ==>Sqoop_Page 4




No comments:
Post a Comment